Thank you all for participating in the recent Future of BESSIG survey (and thank you, Lynn, for putting it together). We had a great discussion at the January meeting and a good response to the survey.
For those that missed it, we talked about three areas: the scope of the group, the name of the group, and a possible funding approach. A number of BESSIG members learned through the AGU ESSI group that the ESSI acronym isn’t well-known or well-understood in the larger geoscience community. Locally, the question came up - do we face the same issues with the BESSIG brand and what would be potential alternatives. As we considered a potential name change, we also discussed expanding or changing the scope of the group to include data science and informatics beyond the current ESSI scope.
Finally, Anne once again raised the question of community funding support, brought to the forefront by the new requirements put forth by our previous meeting place and the difficulties in finding an acceptable meeting space in Boulder.
On to the results!*

| Response | Count | Percent |
|---|---|---|
| Yes, BESSIG should expand to include anyone local interested in data issues, including all scientific domains as well as industry | 16 | 47 |
| Yes, BESSIG should expand to include anyone local interested in academic science data issues, including all scientific domains but not industry | 7 | 20 |
| No, BESSIG should remain an Earth Space Science-focused group | 5 | 15 |
| Other | 6 | 17 |

| Response | Count | Percent |
|---|---|---|
| Yes | 3 | 9 |
| No | 5 | 15 |
| Depends on how awesome the new name is | 24 | 70 |
| I don't care either way, I am just in it for the beer | 2 | 6 |
So we’re not sure about the name change. Some of the suggestions:
- Boulder Planetary Data or Boulder Earth Data
- BDIG (Boulder Data on the Ground)
- BADTAP (Boulder Area Data in Theory and Practice)
- B DISH (Boulder Data Interoperability Starts Here; or flipped as DISH B)
- BADCOP (Boulder Area Data Community-of-Practice)
- Boulder Data Masters
- Boulder Data Group
- Boulder Data Whisperers
- FREDS (Front Range Earth Data Society)
- FREIDA (Front Range Informatics and Data Association)
- BADS Group (Boulder Area Data Science Group)
- BAFOD (Boulder Area Friends of Data)
- DIGBA (Data Interest Group, Boulder Area)
- BESDIG (Boulder Earth Science Data Interest Group)
- BAD ASS (Boulder Area Data Art and Sciences Society)
A word of caution here - there are a number of existing data science meetups in Boulder and we need to take into consideration the names of those groups before selecting a new name here. BESSIG is pretty unique; Boulder Data Science is not.
And another valid comment - it depends on the outcome of the scope question. If we expand beyond Earth and Space Sciences, shouldn’t the name reflect that?
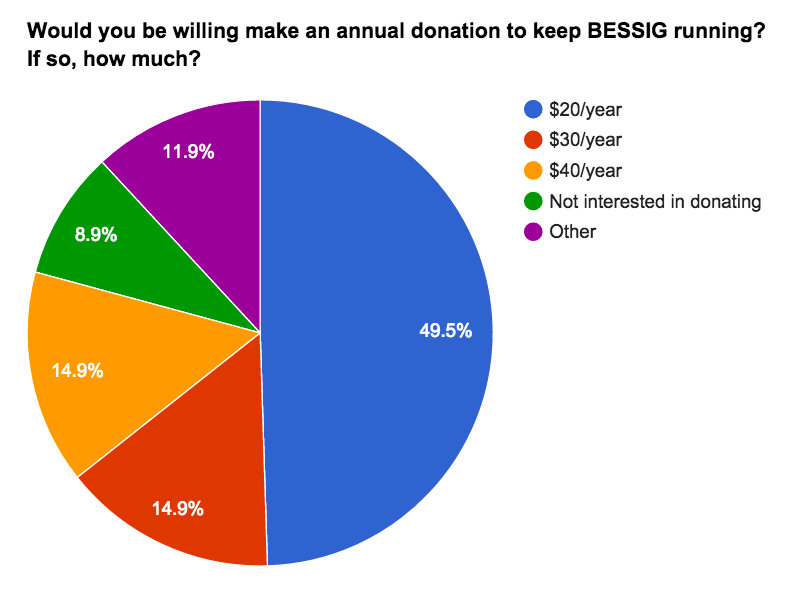
| Response | Count | Percent |
|---|---|---|
| $20/year | 17 | 50 |
| $30/year | 5 | 15 |
| $40/year | 5 | 15 |
| Not interested in donating | 3 | 9 |
| Other | 4 | 12 |
Here, a majority of the respondents are willing to contribute some funds to support BESSIG. (This is voluntary and in no way reflects a desire to impose dues.)
Finally, from the set of additional comments space, we see a couple of trends. First, the meeting time is an issue for some folks. And second, there’s a hesitation in expanding the scope outside of academics or the sciences, i.e. what do we lose if the scope is too broad?
We’ve learned a lot from just the three questions. The most important takeaway is that there’s a lot of support to keep this community going and growing. And thank you, Anne, for keeping it going for the past five years!
(For anyone interested in the complete survey results, they're available as a Google sheet.)
* Since we are, at heart, a bunch of data geeks, the percents in the tables and in the charts vary due to Fun With Rounding across the two visualization options. The bins are big enough not to quibble, yes?
![]() We're meeting at the Gondolier, http://www.gondolierboulder.com/, who are providing us this space for free. In searching for a venue, I have learned how rare and special it is for a business to provide this. Please come and order something so that the Gondolier can continue to offer us this space.
We're meeting at the Gondolier, http://www.gondolierboulder.com/, who are providing us this space for free. In searching for a venue, I have learned how rare and special it is for a business to provide this. Please come and order something so that the Gondolier can continue to offer us this space. ![]()
Leveraging Internet Identity for Scientific Collaborations
Ken Klingenstein, Evangelist, Digital Identity & Privacy, Internet2
In the last several years there has been rapid development of an identity layer for the Internet. Efforts in government, R&E, businesses and among social identity providers are creating an infrastructure of identity and attributes that is being leveraged to access supercomputers, social sites, health care providers, federal research agencies, instrumentation and databases, cloud based storage and compute services, etc.
The two major areas in this work are federated identity, which allows local identities, authentication and attributes to be used Internet-wide, and collaboration platforms, which allow virtual organizations and other multi-institutional efforts to build on federated identity and seamlessly use a growing pool of collaboration applications (wikis, listservs, file sharing, code management tools, command line apps, etc).
This talk will discuss the current state of federated identity, including international inter-federation and US government activities, and how federated identities are being used in leading-edge US science communities. It will then present the emergence of collaboration platforms, and their ability to integrate access control and group management across collaboration applications using open standards. Demos might happen; interruptions and comments most welcome.
Schedule (more or less)
4:00 - 5:00 Presentation
5:00 - 6:00 Social
Identifiers & Relationships
Joe Hourcle, Solar Data Analysis Center, Goodard
At a recent meeting, I came to realize that there are quite a few people who have more recently come into the field of data informatics, and have missed out on much of the discussions over the last decade on data identifiers. In the last few weeks two papers were published by some of the same co-authors that took a contrary position on the presentation of identifiers, although that was not a focus on either of the papers.
I will give an overview of some of the issues regarding identifiers for data (both those that I think are resolved and not), the need for vocabulary and standards to describe what is being identified, and the implications for data citation and describing other data relationships.
Bio:
Joe Hourcle is (as of the time this was written) a programmer/analyst for the Solar Data Analysis Center at Goddard Space Flight Center, working as a programmer / DBA / sysadmin / cataloger / whatever else on the Virtual Solar Observatory. He has an interest in classifying things and naming concepts -- he has been working with Todd King on a (still unpublished) vocabulary to discuss data systems (http://virtualsolar.org/vocab), and back before he knew anything about ontologies & controlled vocabularies, added the topics to fark.com. He would also like to remind you that the crew neck means that most t-shirts qualify as a 'shirt with a collar'.
![]() We'll be meeting at the Gondolier, http://www.gondolierboulder.com. The restaurant is in the Meadow's Shopping Center, on the southwest corner of Baseline and Foothills. We'll meet in their back room.
We'll be meeting at the Gondolier, http://www.gondolierboulder.com. The restaurant is in the Meadow's Shopping Center, on the southwest corner of Baseline and Foothills. We'll meet in their back room.
The Gondolier is providing us this space for free. In searching for a new venue, I have learned how rare and special it is for a business to provide this. Please come and order something so that the Gondolier can continue to offer us this space.
What's an Ontology and What Should I Do With It?
Beth Huffer, Lingua Logica
The word "ontology" is used to refer to a variety of different artifacts, from controlled vocabularies that serve as glossaries, to formal ontologies that serve as data schemas for graph databases and/or deductive reasoning systems. This talk will focus on use cases for formal ontologies, with a demonstration of and presentation on ODISEES (Ontology-Driven Interactive Search Environment for Earth Science) which was recently released in beta by the Atmospheric Science Data Center at NASA Langley Research Center. ODISEES provides a parameter-level search environment for discovering ASDC data resources, enabling users to specify a precise set of criteria and get a set of results that exactly match those criteria. Following an overview of the technology behind ODISEES, Beth will discuss additional use cases for formal ontologies of the sort driving ODISEES.
Schedule (mostly)
4:30 - 5:30 Presentation
5:30 - 6:00 Social
![]() We have a new venue! We'll be meeting at the Gondolier, http://www.gondolierboulder.com. The restaurant is in the Meadow's Shopping Center, on the southwest corner of Baseline and Foothills. We'll meet in their back room.
We have a new venue! We'll be meeting at the Gondolier, http://www.gondolierboulder.com. The restaurant is in the Meadow's Shopping Center, on the southwest corner of Baseline and Foothills. We'll meet in their back room.
The Gondolier is providing us this space for free. In searching for a new venue, I have learned how rare and special it is for a business to provide this. Please come and order something so that the Gondolier can continue to offer us this space.
Who's Afraid of File Format Obsolescence?
Evaluating File Format Endangerment Levels and Factors for the Creation of a File Format Endangerment Index
Heather Ryan, University of Denver Library and Information Science
Much digital preservation research has been built on the assumption that file format obsolescence poses a great risk to the continued access of digital content. In an endeavor to address this risk, a number of researchers created lists of factors that could be used to assess risks associated with digital file formats. My research examines these assumptions about file format obsolescence and file format evaluation factors with the aim of creating a simplified file format endangerment index.
This study examines file format risk under the new lens of 'file format endangerment,' or the possibility that information stored in a particular file format will not be interpretable or renderable in human accessible means within a certain timeframe. Using the Delphi method in two separate studies, this exploratory research collected expert opinion on file format endangerment levels of 50 test file formats; and collected expert opinion on relevance of 28 factors as causal indicators of file format endangerment.
Experts expressed the belief that generally, digital information encoded in the rated file formats will be accessible for 20 years or more. This indicates that file format experts believe that there is not a great deal of short-term risk associated with encoding information in the rated file formats, though this does not preclude continued engagement with preservation activities for these and other file formats. Furthermore, the findings show that only three of the dozens of file format evaluation factors discussed in the literature exceeded an emergent threshold level as causal indicators of file format endangerment: 'Rendering Software Available,' 'Specifications Available,' and 'Community/3rd Party Support.' Consequently, these factors are ideal candidates for use in a simple file format endangerment index that can be used to assess endangerment levels of any file format.
The findings of this study have implications for further exploration of file format endangerment in specific digital information creation domains. In particular, applying this model to file formats created by and used in the Earth and Space Science communities will both strengthen the model and will produce valuable insight into format-centric Earth and Space Science data creation and management practices. This insight can then be applied to risk assessment and subsequent actions to support continued access to datasets over time.
Come join us!
We're still at the Outlook through April 2014. We seek an alternative venue for May and beyond. Please see New Venue Desirements below and keep them in mind as you move around Boulder.
![]() Note that we'll start at 4:15 this month due to our speaker's schedule.
Note that we'll start at 4:15 this month due to our speaker's schedule.
![]() This month marks the 3rd anniversary of the BESSIG!
This month marks the 3rd anniversary of the BESSIG!
An Easy Bake Semantic Metadata Repository for Scientific Data
Mik Cox, Tyler Traver, Anne Wilson, Doug Lindholm, Laboratory for Atmospheric and Space Physics (LASP), Don Elsborg, CU Faculty Affairs
This presentation will discuss the use of open source tools and the tasks that remained to create a semantically enabled metadata repository.
The LASP Interactive Solar Irradiance Data Center, LISIRD, is a web site that serves the lab's solar irradiance and related data products to the public. LISIRD provides information about the data it offers as part of its web page content, embedded in static HTML. At the same time, other LASP web sites also provide the same information, such as sites pertaining to specific missions or education and outreach. Keeping data set information updated and in sync across web sites is a problem. Nor is the information interoperable with emerging search and discovery tools.
To address this and other issues, we created a semantically enabled metadata repository that holds information about our data. In conjunction, we prototyped a new implementation of LISIRD that dynamically renders page content, pulling metadata from the repository and including in the page current, vetted metadata from a single, definitive source. Other web pages can similarly pull this information if they choose. Additionally we can now offer new semantic browse and search capabilities, such as search of data sets by type (currently spectral solar irradiance, total solar irradiance, and solar indices) or over a particular spectral range provided by the user.
We can also render the metadata in various formats understandable to other communities, such as SPASE for the heliophysics community and ISO for the international community. This will allow us to federate with sites that use those formats, allowing broader discovery of our data.
To date, metadata management at LASP has generally been done on a per project, ad hoc basis. We are building applications on top of the repository that provide CRUD (create, read, update, delete) capabilities for metadata records to metadata 'owners' and 'curators'. We expect this to help data managers to store and manage their metadata in a more rigorous fashion should they choose to use it.
We heavily leveraged existing open source tools to create the repository. In this talk we'll talk about using VIVO to create a semantic database, LaTiS to fetch data and metadata, and AngularJS to write dynamic, testable JavaScript. We'll describe our experiences extending two existing ontologies to meet our space physics domain needs.
With these tools and some student time (though our students are exceptional) we are achieving significantly increased capabilities at a relatively low cost. We believe this tool combination could help projects with limited resources achieve similar capabilities to manage and provide access to metadata.
And, if that's not easy-bake enough for you, try this PC EZ-Bake Oven, made especially for geeks: http://www.thinkgeek.com/stuff/41/ezbake.shtml.
Schedule (mostly)
4:15 - 5:xx presentation
5:xx - 6:00 social
New Venue Desirements
Free, or cost based on attendance
Can purchase food and beverages, or within walking distance of such
Easy to get to, easy to park, in Boulder
Separate room
Projection capability
Internet connectivity
hours 4:00 - 6:00 Tu or Wed, 2nd, 3rd, or 4th week of the month, flexible
We're still at the Outlook through April 2014. We seek an alternative venue for May and beyond. Please see New Venue Desirements below and keep them in mind as you move around Boulder.
![]() Note that we're meeting on a Tuesday rather than a Wednesday this month due to room availability. We're back in the Chatauqua room at the Boulder Outlook Hotel.
Note that we're meeting on a Tuesday rather than a Wednesday this month due to room availability. We're back in the Chatauqua room at the Boulder Outlook Hotel.
Earth System CoG and the Earth System Grid Federation: A Partnership for Improved Data Management and Project Coordination
Sylvia Murphy, Cecelia DeLuca, Allyn Treshansky, NOAA/CIRES, Luca Cinquini, JPL/NOAA
The Earth System CoG Collaboration Environment, led by a NOAA ESRL/CIRES team, is partnering with the DOE-led Earth System Grid Federation (ESGF) data archive to deliver a capability that will enable users to store, federate, and search scientific datasets, and manage and connect the projects that produced those datasets.
ESGF is an international network of data nodes that is used to host climate data sets, including the model outputs from the Coupled Model Intercomparison Project (CMIP), which supported the Intergovernmental Panel on Climate Change (IPCC) assessment reports. ESGF data nodes are federated, so that all data holdings are visible from any of the installation sites. An ESGF data node is now installed at NOAA’s Earth System Research Laboratory (ESRL’s). It currently hosts data from the Dynamical Core Model Intercomparison Project (DCMIP) and Twentieth Century Reanalysis data from ESRL’s Physical Sciences Division.
CoG is a collaboration environment and connective hub for networks of projects in the Earth Sciences. It hosts software development projects, model intercomparison projects, and short university-level courses. It includes a configurable search to data on any ESGF node, metadata collection and display, project-level wikis, and a host of other capabilities. There are 74 projects currently using the system.
CoG is partnering with the international Earth System Model Documentation (ES-DOC) project, funded by both NOAA and the EU’s Infrastructure for the European Network for Earth System Modeling (IS-ENES) project. ES-DOC is developing tools that capture, display, and compare Earth system model metadata. This information can be linked directly from a CoG project or attached to specific datasets in the ESGF node.
This presentation will provide an overview of both CoG and ESGF, demonstrate data discovery and download, and key CoG capabilities using relevant example projects.
CoG: https://earthsystemcog.org/
ESRL ESGF data node: http://hydra.fsl.noaa.gov/esgf-web-fe/
Schedule (mostly)
4:00 - 5:xx presentation
5:xx - 6:00 social
New Venue Desirements
Free, or cost based on attendance
Can purchase food and beverages, or within walking distance of such
Easy to get to, easy to park, in Boulder
Separate room
Projection capability
Internet connectivity
hours 4 - 6:00 Tu or Wed, 2nd, 3rd, or 4th week of the month, flexible
We're still at the Outlook through April 2014. We seek an alternative venue for May and beyond. Please see New Venue Desirements below and keep them in mind as you move around Boulder.
![]() Note that this meeting will be held in the Panorama Room of the Outlook Hotel instead of our usual Chatauqua room. This means that we won't have a server and food and drinks must be ordered in the restaurant.
Note that this meeting will be held in the Panorama Room of the Outlook Hotel instead of our usual Chatauqua room. This means that we won't have a server and food and drinks must be ordered in the restaurant.
Accessing Data Instead of Ordering Data: A New Normal
Michael Little, the Advanced Development Systems Engineer at the Atmospheric Science Data Center (ASDC)
Mike will describe how the new generation of research objectives will need to avoid staging data locally from multiple modeling and observational repositories. Rather, new access methods will present a machine-to-machine interface which permits codes and software applications to retrieve small increments of data continuously as part of the processing. The ASDC's Data Acess architecture will be described with a particular emphasis on iRODS as one of the most promising tools for remote access to data held in earth science data centers.
Mike's slides for this talk are available here: DataDistributionArchitecture_0.4.3.pptx.
Schedule (mostly)
4:00 - 5:xx presentation
5:xx - 6:00 social
New Venue Desirements
Free, or cost based on attendance
Can purchase food and beverages
Easy to get to, easy to park, in Boulder
Separate room
Projection capability
Internet connectivity
hours 4 - 6:00 Tu or Wed, 2nd, 3rd, or 4th week of the month, flexible
We're still at the Outlook through April 2014. We seek an alternative venue for May and beyond. Please see New Venue Desirements below and keep them in mind as you move around Boulder.
Deep Carbon Observatory - Data Science and Data Management Infrastructure Overview and Demonstration
Patrick West, Rensselaer Polytechnic Institute
The Deep Carbon Observatory (DCO) brings together hundreds of organizations and individuals from all around the world, spanning a great many scientific domains with a focus on Carbon. The DCO Data Science team is anticipating the generation of terabytes of information in the form of documents, scientific datasets from level 0 to data products and visualizations, information about events, people, and organizations, and more. So how do we keep track of all of this information, manage the information, and disseminate the information?
In order to organize all of this information and provide the research community the tools necessary to collaborate and do their research, the DCO Data Science team is putting together a suite of tools that will integrate all of these components in a seamless, distributed, heterogeneous environment. This presentation and demonstration will provide an overview of the work that we, the DCO Data Science team, are doing to provide such an environment.
Due to Patrick's schedule, we'll plan on starting at 4:15 instead of 4:00.
Here are Patrick's slides: http://tw.rpi.edu/web/doc/DCO-DS-Overview-Demonstration-BESSIG.
Schedule (mostly)
4:15 - 5:xx presentation
5:xx - 6:00 social
New Venue Desirements
Free, or cost based on attendance
Can purchase food and beverages
Easy to get to, easy to park, in Boulder
Separate room
Projection capability
Internet connectivity
hours 4 - 6:00 Tu or Wed, 2nd, 3rd, or 4th week of the month, flexible
Our meeting this month is a special event for several reasons. Copies of Andrew's book will be available to the first 50 attendees, and the HDF Group will be providing refreshments for us. Also, this may be our last meeting at the Boulder Outlook Hotel, as the hotel has been sold. So, please join us in the Crown Rock room (not our usual room) at the Outlook for:
Improving Science with Open Formats and High-Level Languages: Python and HDF5
Andrew Collette, Laboratory for Atmospheric and Space Physics (LASP)
This talk explores how researchers can use the scalable, self-describing HDF5 data format together with the Python programming language to improve the analysis pipeline, easily archive and share large datasets, and improve confidence in scientific results. The discussion will focus on real-world applications of HDF5 in experimental physics at two multimillion-dollar research facilities: the Large Plasma Device at UCLA, and the NASA-funded hypervelocity dust accelerator at CU Boulder. This event coincides with the launch of a new O’Reilly book, Python and HDF5: Unlocking Scientific Data, complimentary copies of which will be available for attendees.
As scientific datasets grow from gigabytes to terabytes and beyond, the use of standard formats for data storage and communication becomes critical. HDF5, the most recent version of the Hierarchical Data Format originally developed at the National Center for Supercomputing Applications (NCSA), has rapidly emerged as the mechanism of choice for storing and sharing large datasets. At the same time, many researchers who routinely deal with large numerical datasets have been drawn to the Python by its ease of use and rapid development capabilities.
Over the past several years, Python has emerged as a credible alternative to scientific analysis environments like IDL or MATLAB. In addition to stable core packages for handling numerical arrays, analysis, and plotting, the Python ecosystem provides a huge selection of more specialized software, reducing the amount of work necessary to write scientific code while also increasing the quality of results. Python’s excellent support for standard data formats allows scientists to interact seamlessly with colleagues using other platforms.
Schedule (more or less)
4:00 - 5:00 presentation
5:00 - 6:00 social
Regridding of data is a common problem faced by many scientific software developers. If regridding is part of your world, this talk may be of interest to you. Come join us at the Boulder Outlook Hotel for this month's talk:
There is more to conservative interpolation--- interpolating edge and face centered fields in the geo-sciences
Alexander Pletzer, Tech-X
Interpolation is one of the most widely used postprocessing tasks, according to a survey of Ultrascale Visualization Climate Data Analysis Tools (UV-CDAT) users. Most geo-postprocessing tools (UV-CDAT, NCL, Ferret, etc) support a choice of both bilinear and conservative regridding with conservative interpolation guaranteeing that the total amount of "stuff" (energy, water, etc) remains unchanged after regridding. The SCRIP and ESMF are examples of libraries implementing these interpolation methods.
We argue that the type of interpolation is dictated by the type of field and that cell centered fields require conservative interpolation whereas nodal fields require bilinear (or higher order) interpolation. Moreover, the wind velocity fields used by finite-volume atmospheric codes, which are neither cell-centered nor nodal but face-centered (Arakawa D staggering), require different interpolation formulas. Interpolation formulas of face-centered and edge-centered (Arakawa C) fields have been known as Whittney forms since 1957 and are widely used in electromagnetics. We present interpolation methods new to the geo-sciences that conserve flux and line integrals for Arakawa D, respectively Arakawa C, stagggered fields.
This talk should be of interest to anybody in need to regrid velocity and other vector fields whose components are staggered with respect to each other.
Schedule (mostly)
4:00 - 5:00 Presentation
5:00 - 6:00 Social
"Code without tests is bad code. It doesn't matter how well written it is; it doesn't matter how pretty or object-oriented or well-encapsulated it is. With tests, we can change the behavior of our code quickly and verifiably. Without them, we really don't know if our code is getting better or worse." [FEATHERS]
A strong statement, but it does bring home the vital role of testing in software development. Join us at the Boulder Outlook Hotel for:
Strategies, motivations, and influencing adoption of testing for scientific code
Ian Truslove, Erik Jasiak, NSIDC
Computation and programming are increasingly inescapable in modern Earth Sciences, but scientists and researchers receive little or no formal software engineering or programming training. At the same time, research into the reproducibility of other academic papers exposing disappointingly low rates of repeatability and high-profile retractions due to computational or data errors increase the onus on researchers to write repeatable, reliable, even reusable programs; in other words, "write better code".
Software engineering has plenty to say on the matter of "better code": metrics, methodologies, processes, tools... Of course, none are indisputable and none provide absolute guarantees. One seemingly obvious technique - testing - has enjoyed a renaissance in incarnations such as unit testing, and with approaches such as test-driven development (TDD) and behavior-driven development (BDD).
Based on our experience at the National Snow and Ice Data Center (NSIDC) with unit testing, TDD and BDD, we present a set of recommendations to scientific and research programmers about some techniques to try in their day to day programming, and possibly provide some inspiration to aim for more comprehensive approaches such as BDD. We will highlight some use cases of various types of testing at the NSIDC, discuss some of the cultural and management changes that occurred for programmers, scientists and project managers to consider and adopt processes such as TDD, make recommendations about how to introduce or expand rigorous code testing practices in your organization, and discuss the likely benefits in doing so.
[Scroll down to see post presentation references and material.]
Schedule
4:00 - 5:00 Presentation
5:00 - 6:00 Social
All are welcome.
Post Presentation References and Material
Wilson et al, "Best Practices for Scientific Computing", highly recommended!
Merali, "Computational science: ... Error" in Nature. "As a general rule, researchers do not test or document their programs rigorously, and they rarely release their codes, making it almost impossible to reproduce and verity published results generated by scientific software, say computer scientists."
Good books for unit testing, TDD, and higher-level tests
Freeman and Pryce, Growing Object-Oriented Software, Guided by Tests
Beck, Test Driven Development: By Example
Fowler, Mocks Aren't Stubs - Martin Fowler on the terminology and usage of mocks, stubs, test doubles - all those "fake collaborators"
A couple of Bob Martin's books are particularly noteworthy for covering lots and lots of desirable attributes for code
Martin, Agile Software Development, Principles, Patterns, and Practices
Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Some test frameworks
JUnit - the original (Java)
RSpec (Ruby)
Behave (Python)
Jasmine (JavaScript)
mgunit (IDL)
pfUnit (FORTRAN)
Cucumber (Acceptance tests, lots of languages)
Also
Feathers, Michael C., Working Effectively with Legacy Code , Prentice Hall, 2005, p. xvi.
Snowden, Cynefin: Wikipedia on Cynefin, David Snowden introducing Cynefin (video) - applicable to knowledge management, cultural change, and community dynamics, and has also involved issues of organizational strategy.
Snowden, Boone, 2007 "A Leader's Framework for Decision Making" (must pay for access from Harvard Business Review, though perhaps available elsewhere)
NSIDC's and ultimately Boulder's loss of Mark Parsons is RDA's gain. But maybe that's better for the world as a whole. Join us at the Boulder Outlook Hotel on August 21 to hear about the Alliance Mark has joined.
The Research Data Alliance: Creating the culture and technology for an international data infrastructure
Mark Parsons, Managing Director, Research Data Alliance/U.S.
All of society’s grand challenges -- be it addressing rapid climate change, curing cancer and other disease, providing food and water for more than seven billion people, understanding the origins of the universe or the mind -- all of them require diverse and sometimes very large data to to be shared and integrated across cultures, scales, and technologies. This requires a new form and new conception of infrastructure. The Research Data Alliance (RDA) is creating and implementing this new data infrastructure. It is building the connections that make data work across social and technical barriers.
RDA launched in March 2013 as a international alliance of researchers, data scientists, and organizations to build these connections and infrastructure to accelerate data-driven innovation. RDA facilitates research data sharing, use, re-use, discoverability, and standards harmonization through the development and adoption of technologies, policy, practice, standards, and other deliverables. We do this through focussed Working Groups, exploratory Interest Groups, and a broad, committed membership of individuals and organizations dedicated to improving data exchange.
What data sharing problem are you trying to solve? Find out how RDA can help.
Schedule
4:00 - 5:00 Presentation
5:00 - 6:00 Social
Please join us!
In July we're meeting in the 4th week of the month, rather than the 3rd. Please join us at the Boulder Outlook Hotel for our own Ted talk:
HDF and The Earth Science Platform
Ted Habermann, The HDF Group
Interoperable data and understanding across the Earth Science community requires convergence towards a standard set of data formats and services, metadata standards, and conventions for effective use of both. Although large legacy archives still exist in netCDF3, HDF4, and many custom formats, we have achieved considerable convergence in the data format layer with the merger of the netCDF4 and HDF5 formats. The way forward seems clear as more groups in many disciplines join the HDF5 community. The data service layer has experienced similar convergence as OGC Service Standards are adopted and used in increasing numbers and connections across former chasms are deployed (ncWMS, ncSOS, netCDF/CF as OGC Standards). Many data providers around the world are in the process of converging towards ISO Standards for documenting data and services. Connections are also helping here (ncISO). Many groups are now working towards convergence in the conventions layer. The HDF-EOS and Climate-Forecast conventions have been used successfully for many datasets spanning many Earth Science disciplines. These two sets of conventions reflect different histories and approaches that provide a rich set of lessons learned as we move forward.
Schedule
4:00 - 5:00 Presentation
5:00 - 6:00 Social
Stop on by!
This month we'll meet again the Boulder Outlook Hotel for:
Py in the Sky: IPython and other tools for scientific computing
Monte Lunacek, Application Specialist, CU Research Computing
Roland Viger, Research Geographer, USGS
Python offers a rich toolkit that is useful for scientific computing. In this talk, we will introduce the IPython package and discuss three useful components: the interactive shell, the web-based notebook, and the parallel interface. We will also demonstrate a few concepts from the Pandas data analysis package and, time permitting, offer a few tips on how to profile and effortlessly speedup your python code. This talk will describe and illustrate these tools with example code. If Python is not your favorite programming language, this overview might change that.
Schedule
4:00 - 5:00 Presentation
5:00 - 6:00 Social
Come on by!